Trying to help the technically challenged... so mainly myself.
日本語訳が必要な方は、コメントをください。
Happy Sys Admin Day!
Get link
Facebook
X
Pinterest
Email
Other Apps
Happy Sys Admin Day!! Hope your boss or groups you work with appreciate the day to day work on the dark side of the moon you do everyday. http://www.sysadminday.com/
NPE-240A Summary: Just had a new tankless water heater installed in my house to replace a failing 22 year-old 50 gallon tank. Couldn't be happier w/ my new tankless, but was dealing with weirdness on the Navilink app to control/view my new Navien . The app's scheduling function (for the recirculation pump) was missing. Solution: NR-20DU Disconnect NR-20DU remote controller. (if you want to schedule via App) *DIP Switches need to be set properly as well. In my case, w/ a bridge valve in my furthest faucet, is considered "External Recirculation". Check w/ your plumber for proper settings, they set mine properly. If you are in the Atlanta area, I highly recommend Plumbing Express LLC . Ask for Jonathan DeWeese. For reference only, these were set correctly by my plumber for my setup. DIP Switch 1 Off, 2 On. (Internal Recirculation would be the opposite) Parameter 18 set to On (This is to enable Navilink ) These settings are detailed out in t...
I thought because Sprint did not provide software to tether my blackberry to my mac, I would not be able to use it as a modem. Well, it's not exactly real easy like most things on the mac, but not terribly difficult either. What follows is instructions on how to make this happen w/ a Sprint Blackberry 8830. [ Update: These steps work for Leopard and Snow Leopard ] [Before you begin, make sure you're Sprint account is enabled for data tethering, there is usually an extra charge for this service] What follows are some instructions to get this to work in Leopard (OSX 10.5.x): Click the Apple icon and select preferences. Next, click the bluetooth icon. Now click the plus (+) button. A setup wizard should start. Follow the wizard's instructions to pair your phone. Make sure your blackberry is in discovery mode so the mac can see it when it searches for it Once you've paired your blackberry, you should see it in your bluetooth preferences like picture below. Highlight your bl...
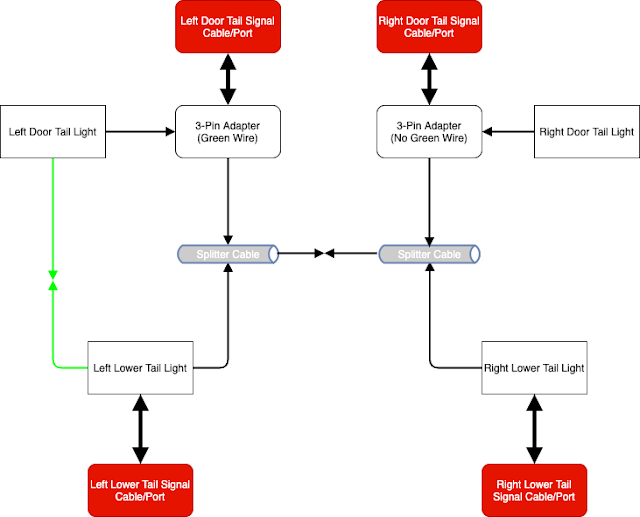
Summary: As a little treat for myself, I bought some real cool aftermarket tail lights from Hansshow as you can see from the video above. Use coupon code "SARHANSSHOW" for 15% off. I don't get a cut of any kind, but I like sharing. Anyway, here is a wiring diagram I drew up to show how everything logically needs to be wired. If you want to support me and posts like this, you can order Tesla products via my referral link . Honestly, their referral program these days is kinda lame in my opinion, but hey, you get something and I get something out of it. Notes: For euro spec may be slightly different and 2021 models would use a 4-pin Adapter instead of a 3-pin adapter which is US specific and applies for 2020 models and older. Basically, if you have a red turn signal, chances are that you have a 3-pin setup. The only downside to these lights in older models is that the turn signal indicators light up in addition to a separate red brake light on the...



Comments