vSAN: The cascade scenario that vSAN stretch cluster has issues with...

Basically while testing stretch cluster, we ran into strange failover behavior. The fact that it was not simply occuring. During this testing, we found a dirty little secret about stretch cluster failovers. One that makes me rethink if stretch clusters really is worth doing.
Details:
All documented scenarios effectively deal w/ a 'single' type of failure. The problem is disasters/failures can be multi-faceted and cascading in some instances. Taking the Secondary Site Failure or Partitioned scenario and adding the 'cascading failure' to it and you end up in a whole world of trouble depending on the next 'failure'.
Below effectively depicts the failure of the interconnect between the two sites. The problem this fails to take into account is that there are typically 3 things involved to this.
- The networking between the two sites
- The preferred site routers
- The secondary site routers

So here is a slightly more involved diagram to highlight a case where the primary site routers link to the secondary site fails FIRST in a cascading failure scenario.

- VMs in Secondary Site are HA powered off
- VMs in Secondary Site are powered on in Preferred Site.
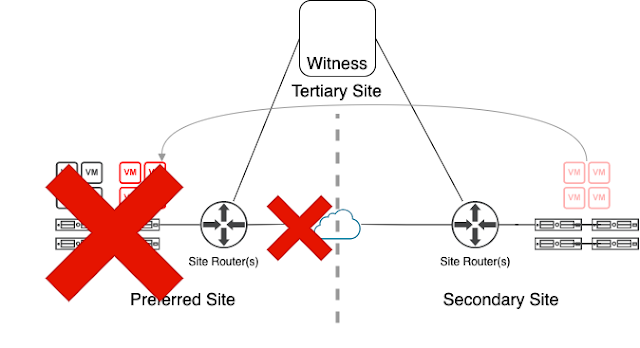
Witness cannot send preferred site a signal to HA event because it does not know its actual status to start systems on secondary site. The data on secondary site has also been declared stale at this point because the link between preferred and secondary was broken first. This is not an issue if secondary site were the one to fail.
- Restore from backup
- Contact VMware for the black magic voodoo to force a failover to secondary site.
Release the black magic voodoo so that you can force failover to your secondary site?
It's somewhat of an edge case, but in a DR scenario, anything is possible.
Is vSAN stretch cluster worth it?
I'd argue probably not, knowing the behavior above. I'd be more likely to lean toward DR tools like SRM (even though it wouldn't be real time replication). Or rely on application level replication tech. However, I'm sure there are use cases where vSAN stretch cluster would make sense, but the very real failure scenario above definitely gives me pause.


Comments